Como su nombre indica, un concentrador VPN no es mas que un equipo que se encarga de aglutinar todas las conexiones VPN de nuestros clientes, ya bien sea de nuestros puestos de trabajo como de sedes remotas conectadas a través de Internet de una forma segura. En nuestro caso vamos a realizar una configuración Site-to-Site que normalmente se utiliza para conectar dos o más sedes remotas y enrutar el direccionamiento LAN entre los distintos clientes.

Lo primero que debemos hacer es instalar el software del servidor. Por manias o costumbres que tiene cada uno, además de instalar el paquete openvpn siempre me gusta instalar las utilidades User Mode Linux (uml-utilities) que no son necesarias pero yo lo hago. Una vez hecho esto, debemos crear nuestra infraestructura de clave pública (PKI) que utilizaremos a la hora de conectar nuestros equipos.

Para la creación de todos los certificados utilizaremos easy-rsa y como ya comenté en entradas anteriores, en la versión Wheezy de Debian viene integrado en la documentación del paquete. Concretamente, en la ruta /usr/share/doc/openvpn/examples/easy-rsa/2.0/ que es donde está alojada la última versión de los scripts. Lo primero que haremos será editar el fichero de configuración vars para adecuarlo a nuestra infraestructura.

Una vez guardados los cambios del fichero, que no son más que variables como su nombre indica, deberemos aplicarlo en el sistema. Para ello ejecutamos la comando source vars ó . vars desde el directorio raíz de easy-rsa y obligatoriamente tendremos que ejecutar el script clean-all si es la primera vez que lo utilizamos. Mención especial a que dicho script nos borra el directorio donde se generan los certificados por lo que mucho cuidado de ejecutarlo si no tenemos un backup de los mismos.
Una vez tenemos realizada la configuración para nuestra infraestructura, lo primero que hay que hacer es crear nuestra Certificate Authority y lo realizaremos utilizando el script build-ca. De la siguiente captura, reseñar que el campo Country Name (variable KEY_COUNTRY) utiliza alguna nomenclatura estandar y no puede contener más de dos caracteres por lo que no nos dejará utilizar "Pais" como valor de dicha variable.

Una vez generada nuestra propia CA, lo siguiente que generaremos será la clave con los parámetros Diffie-Hellman y lo creamos utilizando el script build-dh.

Ahora toca el turno de crear el certificado para el servidor VPN, para ello ejecutamos el script build-key-server pasándole como argumento el Common Name con el que queremos que se genere dicho certificado. Será necesario aceptar o modificar las variables globales anteriormente definidas en el fichero vars así como introducir nuevos datos según nos valla pidiendo el script.

A continuación nos muestra la información que va estar visible en el certificado y nos pregunta si queremos firmarlo. La respuesta obvia es si y con ello se genera el Certificate signing request que deberemos confirmar para la creación del certificado.

De igual manera crearemos los certificados de los clientes utilizando el script build-key pasándole nuevamente el CN con el que queremos que se genere el certificado. Aceptaremos y añadiremos los datos que nos vaya pidiendo el script.

Tras ello firmaremos el certificado para generar el CSR y lo confirmamos para creación del mismo al igual que hicimos a la hora de crear el certificado del servidor.

Crearemos tantos certificados clientes como sean necesarios. En el caso que nos ocupa sólo son dos y están almacenados junto con el resto de certificados en un directorio llamado keys dentro de la raiz de easy-rsa.

Copiaremos el certificado de la CA, los parametros DH y del servidor tanto el certificado como la clave privada a la raiz del directorio de configuración. En el caso que queramos almacenar los certificados en otro directorio deberemos especificar la ruta correcta (absoluta o relativa) de los mismos en el fichero de configuración.

No esta de mas decir la importancia que tienen estos ficheros y con mayor relevancia la clave privada de nuestra CA, ca.key. Dentro de la documentación de OpenVPN hay un apartado en el que explica con más detalle toda la creación de la infraestructura PKI y en la que encontramos una tabla (subapartado Key Files) con información de quién necesita cada fichero, por qué y si es necesario mantenerlo a buen recaudo.

Bien, en este punto tenemos toda la configuración de nuestra infraestructura de clave pública preparada para empezar a desplegar el servicio. Dentro de la documentación incluida en el paquete, /usr/share/doc/openvpn, también tenemos a nuestra disposición ficheros de configuración de ejemplo en los que basar nuestras configuraciones tanto para los servidores como los clientes.
Ahora realizamos la configuración del servidor donde modificaremos la directiva local para establecer la IP donde escuchará el servicio, así como las directivas ca, cert, key y dh con los valores del certificado de la CA, certificado del servidor, la clave privada del servidor y el fichero con los parámetros DH respectivamente.
Siguiendo el fichero de configuración, adecuaremos el direccionamiento que vayamos a utiliza con la directiva server y en mi caso me gusta habilitar la directiva client-to-client para que los clientes se puedan ver entre sí pero eso es otro tema. Recomendablemente, activaremos la autenticación TLS con la directiva tls-auth y cambiaremos el algoritmo de cifrado a AES-128-CBC en la opción cipher.
Como última recomendación, para sistemas Linux podemos reducir los privilegios del proceso tras la inicialización del servicio con las directivas user y group. En la siguiente captura se recogen todos los parámetros de configuración con los que podríamos levantar perfectamente el servicio y conectar nuestros clientes de forma satisfactoria.

Antes de ello deberemos generar la clave para la autenticación TLS activada anteriormente. El comando que debemos ejecutar es openvpn --genkey --secret <Name>

Pero nuestra idea es montar un concentrador Site-to-Site, actualmente tenemos la parte del concentrador pero no la del Site-to-Site. Para ello será necesario agregar las algunas directivas al fichero de configuración.

Empezaré comentando topology porque hasta hace poco no lo conocía y me parece un parámetro de configuración muy llamativo, del que no comprendo por qué no está ya implementado por defecto ni siquiera en la rama actual del desarrollo por motivos de retrocompatibilidad.Tal y como dicen en la documentación de la directiva:
"The only real reason to use the net30 topology is when requiring support for Windows clients before 2.0.9, or when any Windows clients must be supported and non-Windows clients must be supported that cannot set IP+netmask on the tun adapter. These conditions are rare, and the 2.0.9 client is around 7 years out of date as of 2014."
El valor por defecto es net30 pero si establecemos el valor a subnet, conseguimos entregar todo el direccionamiento de la red que hayamos especificado en la directiva server entregando una IP por cliente y no utilizar cuatro direcciones por cada uno de ellos. He de reconocer que la versión actual de Wheezy no está compilada a la última versión (OpenVPN 2.2.1 [...] built on Dec 1 2014) pero me parece que 7 años de retrocompatibilidad más otros dos a la fecha actual de una versión obsoleta por unas condiciones muy específicas es un poco exagerado.
Siguiendo con las directivas, la siguiente será client-config-dir en la que especificar, como su propio nombre indica, el directorio que contendrá las opciones de configuración particulares para cada cliente. En dicho directorio, crearemos un fichero de configuración con el CN que hayamos asignado a cada cliente y en cada uno especificaremos la dirección IP que van a recibir con la directiva ifconfig-push, la ruta LAN interna de cada cliente utilizando la directiva iroute así como le publicaremos la ruta del resto de clientes con la opción push junto con la ruta correspondiente.

Ya para ir acabando con todo el tema de la configuración del servidor, queda comentar la directiva route que sirve para anunciarle al mismo las redes por las que se espera recibir o enviar paquetes. Tras todos esos cambios, levantamos el servicio y encontramos una serie de mensajes nuevos en el log del servidor.
"[...]
OpenVPN ROUTE: OpenVPN needs a gateway parameter for a --route option and no default was specified by either --route-gateway or --ifconfig options
OpenVPN ROUTE: failed to parse/resolve route for host/network: <Network IP>
[...]"
Según se lee en el mensaje, nos dice algo de que OpenVPN necesita un gateway para la opción route y no hay valores por defecto en la configuración. Nos está diciendo la directiva que está fallando y tras una pequeña búsqueda, encontramos una solución (seguro que hay más) que es añadirle la IP que utilizará como gateway el servidor VPN para las rutas de los clientes.

Tras reiniciar el servicio, todo funciona correctamente y el log está limpio de errores o advertencias.

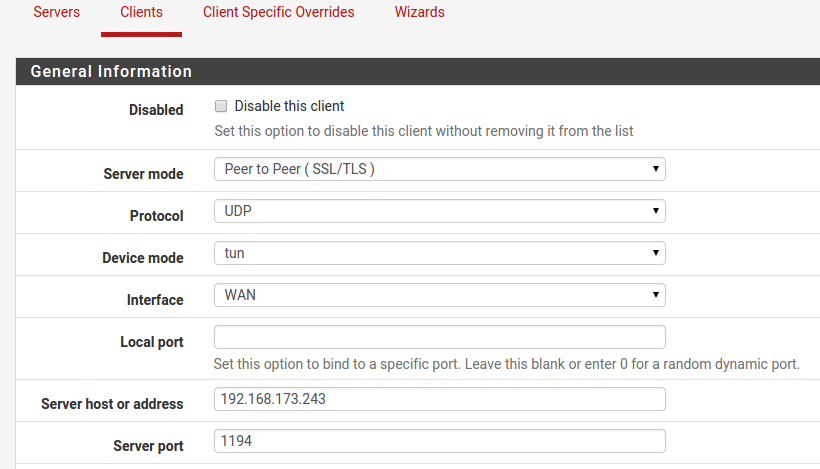
Como la entrada empieza a hacerse un poco larga voy a dividirla en dos, en esta quedaría cubierta toda la parte de la creación de nuestra infraestructura PKI y la configuración del servidor OpenVPN. En la siguiente entrada, realizaré la configuración de un par de clientes basados en pfSense en su última versión así como algunas comprobaciones para corroborar que el sistema funciona correctamente.
Un saludo, Brixton Cat.