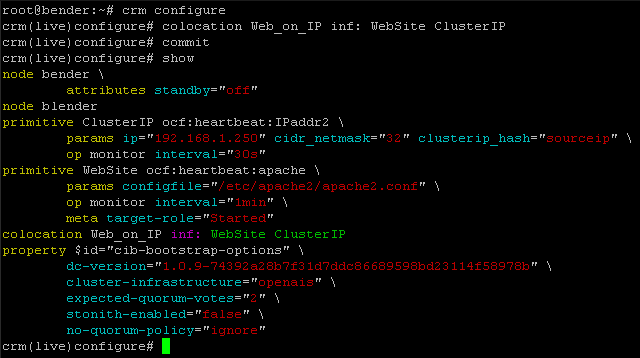
Preparando el sistema
En primer lugar actulizamos la lista de NVTs con el comando openvas-nvt-sync

Luego recargamos la base de datos del gestor (OpenVAS Manager) con el comando openvasmd --rebuild. Recordar que cada vez que actualicemos la lista de test, deberemos lanzar el comando anterior para que el gestor cuente con todas las novedades.

Lanzamos el escaner (OpenVAS Scanner) con el comando openvassd y dejamos que carge los plugins. Comentar sobre este paso que no tarda lo mismo que la primera vez (~ 30min) que ejecutamos el escaner aunque el equipo acabe de ser encendido o reiniciado.

Lanzamos el gestor (OpenVAS Manager) y el administrador (OpenVAS Administrator) con los comandos openvasmd y openvasad, ambos en localhost y en los puertos 9390 y 9393 respectivamente.

Lanzamos el demonio de Greenbone Security Assistant con el comando gsad --http-only --listen=127.0.0.1 -p 9392. Como se puede observar, lanzamos el comando para http (también es posible ejecutarlo bajo SSL) en localhost y en el puerto 9392.
Ejecutamos un navegador y apuntamos a locahost en el puerto 9392 para conectarnos a Greenbonse Security Assistant.

Greenbone Security Assistant
Una vez logueados, crearemos un destino (Target) donde lanzar las pruebas, puede ser un nombre de dominio, un rango o una dirección IP.

Pasamos a crear una nueva tarea con New Task donde elegiremos un nombre, un perfíl de escaneo (Scan Config) y un destino (Scan Targets).

Una vez creada, aparecerá la nueva tarea en el apartado Tasks donde podremos ver más detalles antes de ejecutarla.


Una vez arrancada, el primer estado de la tarea será Requested (Solicitada). Podemos ir actualizando la página para ver el proceso de escaneo y los resultados que va obteniendo.

Una vez finalizada, cambiará a estado Done.

Entrando en la tarea podemos ver un resumen con los datos y los reportes realizados.

Entrando en un reporte vemos más detalles sobre los fallos encontrados y podremos filtrar los resultados y ver sólo los que nos interesen. Igualmente podremos exportarlo a los formatos soportados por el sistema.

No he sido capaz de exportar ningún reporte a PDF, a través de Firefox aparece el siguiente error.

Greenbone Security Desktop
Igualmente nos podemos conectar al demonio de Greenbone a través del escritorio de la misma compañia Greenbone Security Desktop. Lanzamos el comando gsd para ejecutar la aplicación.

Nos logueamos al gestor (OpenVAS Manager), localhost:9390, con algún usuario del sistema. Se puede observar en la captura que el sitema ejecuta la versión 2.0 de OMP (OpenVAS Management Protocol).

En primer lugar nos encontramos los reportes del usuario junto con unos gráficos de los mismos.

Podemos también ver en detalle los reportes realizados al igual que los resultados.

También podemos exportar los reportes. Nuevamente, al exportar a PDF e intentar abrir el documento recibo el error.


Podemos también crear nuevas tareas, targets, temporizadores, etc. a través de las pestañas situadas en la parte inferior de la aplicación.
Con esta entrada finaliza, de momento, la serie BackTrack 5 y los posts relacionados con OpenVAS y los diferentes clientes gráficos que tenemos a nuestra disposición. Espero que sea educativo y entretenido para todos los lectores.
Un saludo, Brixton Cat.